Проектирование Web API
по мотивам «Web API Design - Crafting Interfaces that Developers Love»
- Введение
- Прагматик или RESTафариец?
- Существительные - хорошо, глаголы - плохо
- Существительные во множественном числе и реальные имена
- Упрощая взаимосвязи - прячем сложность за ?
- Обработка ошибок
- Советы по версионированию
- Пагинация и частичный ответ (partial response)
- Как насчет ответов без ресурсов?
- Поддержка различных форматов
- Что насчет имен атрибутов?
- Советы по реализации поиска
- Объединение API в поддомен
- Советы по обработке исключительных ситуаций
- Аутентификация
- Осуществление запросов к API
- Болтливое API (Chatty APIs)
- Предоставление SDK
- Паттерн Фасад для API
- Ресурсы
Введение
Если вы это читаете, то есть шансы, что вы хотите создать Web API, которое полюбят разработчики, и заинтересованы в использовании проверенных архитектурных подходов и лучших практик при работе над ним.
Одним из источников нашего архитектурого мышления является REST. По той причине, что REST является архитектурным подходом, а не строгим стандартом, допустима большая степень гибкости в этом вопросе. Эта гибкость и свобода при выборе структуры являются причиной существования многочисленных лучших практик проектирования.
Эта книга представляет собой набор архитектурных подходов, которые мы разработали в сотрудничестве с некоторыми ведущими командами со всего мира, при создании стратегий для их API в ходе проводимых Apigee семинаров.
Мы назвали наш подход к проектированию API прагматичный REST, т.к. он ставит успех разработчика превыше любых архитектурных принципов. Разработчик является клиентом Web API. Успех принятой архитектуры API заключается в том насколько быстро разработчики в нем разберутся и начнут получать удовольствие от его использования.
Прагматик или RESTафариец?
Давайте начнем с нашего взгляда на проектирование API в целом. Мы придерживаемся прагматичного, а не догматичного REST. Поясним, что имеется в виду под догматичным REST.
Вы, наверное, видели в сети дискуссии о настоящем REST. Некоторые из них довольно топорны и не имеют практической ценности. Mike Schinke хорошо подытожил их определив RESTафарийца следующим образом:
RESTафариец - это ревностный сторонник архитектурного стиля взаимодействия ПО, именуемого REST, в том виде как он определен Роем Филдингом в 5-й главе его дисертации в Калифорнийском университете в Ирвайне. Вы можете встретить RESTафарийцев на полях почтовых рассылок посвященных REST. Но будьте бдительны, RESTафарийцы могут быть предельно щепетильными при обсуждении нюансов REST-подхода…
Наш подход заключается в рассмотрении архитектуры API с изнанки, что означает получение ответа на вопрос “Что мы хотим получить от этого API”?
Цель API заключается в обеспечении успеха разработчика. Основным направлением при работе над API является продумывание архитектурных решений с точки зрения прикладного разработчика.
Почему? Посмотрите на ЦДС (цепочка добавленной стоимости) внизу. Прикладной разработчик является центром притяжения всей стратегии API. Главным архитектурным принципом при разработке API должно быть увеличение продуктивности разработчика и вероятности его успеха. Это и есть то, что мы называем прагматичным REST.
Прагматичный REST - задача проектирования
Вам нужна правильная архитектура, потому что архитектура несет в себе идею того как этим будут пользоваться. Возникает вопрос: Что представляет собой оптимально-полезная для прикладного разработчика архитектура?.
Точка зрения разработчика является ключевым принципом всех представленных ниже советов и практик.
Существительные - хорошо, глаголы - плохо
Правило №1 прагматичной REST-архитектуры звучит так: пусть простое остается простым.
Пусть ваш базовый URL будет простым и интуитивно понятным.
Базовый URL является наиболее важным архитектурным свойством (аффордансом) вашего API указывающим то, каким образом с ним нужно взаимодействовать или использовать. Простой и интуитивный дизайн базового URL упрощает использование вашего API.
Аффорданс - это архитектурное свойство, говорящее о том как чем-то пользоваться не требуя, при этом, документации. Дверные ручки должны сами говорить вам о том, как открывать дверь - на себя или от себя.
Вот пример конфликта между архитектурным аффордансом и документацией, причиной которому - неинтуитивный интерфейс!

Основной критерий проверки, который мы используем при проектировании Web API, является наличие только 2-х URL на каждый ресурс. Давайте смоделируем API для простого объекта или ресурса - собаки (dog), и создадим для него Web API.
Перый URL - для коллекции, второй - для конкретного элемента в коллекции:
/dogs/dogs/1234
Сокращение API до такого уровня также стимулирует к исключению глаголов в базовом URL.
Не используйте глаголы в базовом URL.
Многие Web API в начале используют метод-ориентировнный подход к проектированию URL. Такие URL включают глаголы - иногда в начале, иногда в конце.
Для любого моделируемого ресурса, такого как наша собака, объект, обычно, не рассматривается в изоляции. Всегда существуют связанные и взаимодействующие ресурсы, которые нужно учитывать, такие как владелец, ветеринар, поводок, еда, бЕлки и т.д.
Подумайте о вызовах методов, требуемых для обращения ко всем объектам собачьего мира. URL для наших ресурсов могут иметь следующий вид:

Чем дальше, тем хуже - скоро вы будете иметь длинный список с URL не имеющих единообразия, что усложнит разработчикам изучение и использование вашего API.
Для работы с коллекциями и элементами используйте HTTP-глаголы.
Для нашего ресурса dog имеется два базовых URL, обозначенных существительными, и теперь мы можем работать с ними используя HTTP-глаголы. Наши HTTP-глаголы это: POST, GET, PUT и DELETE (что соответствует аббревиатуре CRUD - Create-Read-Update-Delete).
Имея два ресурса (/dogs и /dogs/1234) и четыре HTTP-глагола мы обладаем широкими возможностями, которые интуитивно понятны прикладному разработчику. Ниже приведена таблица показывающая, что имеется в виду на примере наших собак.
| Ресурс | POST (создание) | GET (чтение) | PUT (обновление) | DELETE (удаление) |
|---|---|---|---|---|
/dogs |
создание новой собаки | список собак | массовое обновление собак | удаление всех собак |
/dogs/1234 |
ошибка | получение Шарика | обновление существующего Шарика, иначе - ошибка | удаление Шарика |
Преимущество в том, что разработчикам, возможно, и не нужна такая таблица чтобы понять как работает API. Они могут поэкспериментировать и изучить API не обращаясь к документации.
В итоге:
- Используйте два базовых URL на каждый ресурс.
- Не используйте глаголы в базовом URL.
- Для работы с коллекциями и элементами используйте HTTP-глаголы.
Существительные во множественном числе и реальные имена
Давайте посмотрим как подобрать существительные для ваших URL.
В каком числе надо брать существительные для именования ваших ресурсов - единственном или множественном? Популярные API используют оба. Давайте посмотрим на примеры:
| Foursquare | GroupOn | Zappos |
|---|---|---|
/checkins |
/deals |
/Product |
Учитывая, что, скорее всего, первое с чего большинство разработчиков начинают знакомство с REST API это GET, мы думаем, что имена ресурсов во множественном числе более удобны и интуитивно понятны при использовании. Но, самое главное, это избегать смешанной модели, когда для одних ресурсов используется единственное число, а для других - множественное. Единообразие способствует тому, что разработчики станут предугадывать вызовы методов по мере изучения вашего API.
Реальные имена лучше абстрактных.
Иногда целью проектировщиков API является достижение чистой абстракции. Однако, эта абстракция может не иметь смысла для прикладного разработчика.
Возьмем, для примера, API которое предоставляет доступ к контенту в различной форме: блогам, видео, новостным статьям и т.д.
API, моделирующее все это на самом высоком уровне абстракции, такое как /items или /assets для нашего примера, не способно дать разработчику ясную картину того, как он может с ним работать. Более наглядным и полезным был бы список таких ресурсов как блоги, видео и новостные статьи.
Уровень абстракции зависит от вашего сценария использования. Вы, также, можете хотеть предоставить умеренное количество ресурсов. Стремитесь использовать значимые имена, поддерживая число ресурсов от 12 до 24.
Короче говоря, интуитивно понятное API использует существительные во множественном числе, и реальные имена вместо абстрактных.
Упрощая взаимосвязи - прячем сложность за ?
В этом разделе мы исследуем аспекты проектирования API касающиеся работы с такими отношениями между ресурсами и параметрами как состояния и атрибуты.
Взаимосвязи
Ресурсы практически всегда имеют связи с другими ресурсами. Как простым образом выразить эти отношения в Web API?
Давайте еще раз вернемся к API которое мы проектировали в разделе Существительные - хорошо, глаголы - плохо - взаимодействие с нашим ресурсом dog. Помните, у нас было два базовых URL: /dogs и /dogs/1234?
Для работы с ресурсами и коллекциями мы использовали HTTP-глаголы. Наши собаки имеют хозяев. Для получения всех собак конкретного хозяина, или для добавления хозяину новой собаки, используйте GET и POST соответственно:
GET /owners/5678/dogs
POST /owners/5678/dogs
Отношения между ресурсами, также, могут быть и сложными. Хозяева обращаются к ветеринарам, которые работают с собаками, которые едят корм и т.д. Нередко можно видеть как люди слепливают эти ресурсы вместе создавая 5-ти или 6-ти ярусные URL. Помните, что когда у вас есть первичный ключ для одного уровня, то, обычно, не нужно наслаивать уровни поверх, т.к. у вас уже есть конкретный объект. Другими словами, необходимость в URL более глубоких, чем приведенные выше, является исключением.
/ресурс/идентификатор/ресурс
Прячем сложность за ?
Большинство API выносят тонкости взаимодействия за пределы базового уровня ресурса. Сложные аспекты включают множество состояний, которые могут обновляться, изменяться, запрашиваться, а также связанные с ресурсом атрибуты.
Облегчите разработчикам использование базового URL размещая необязательные состояния и атрибуты за ?. Получение всех коричневых собак бегающих по парку будет выглядеть следующим образом:
GET /dogs?color=red&state=running&location=park
Подводя итог, поддерживайте свое API интуитивно понятным упрощая взаимосвязи между ресурсами, и пряча параметры и другие сложные вещи за пазуху вопросительного знака HTTP.
Обработка ошибок
Многие разработчики, включая меня, не очень любят думать об ошибках и их обработке, но это очень важная составляющая головоломки для всех разработчиков ПО, и особенно для проектировщиков API.
Почему хороший дизайн ошибок особенно важен для разработчиков API?
С точки зрения разработчика, использующего ваше Web API, все, что находится по ту сторону данного интерфейса, представляет собой черный ящик. Именно поэтому ошибки являются ключевым инструментом обеспечивающим контекст и прозрачность того как пользоваться данным API.
Во-первых, разработчики учатся написанию кода на ошибках. Концепция экстремального программирования test-first и более новый подход TDD представляют собой основу лучших практик, получивших развитие по той причине, что они являются важными и естественными приемами в работе программиста.
Во-вторых, вдобавок к процессу создания приложения разработчики зависят от хорошо спроектированных ошибок в критические моменты отладки и устранения ошибок после того как приложение, использующее API, было передано в руки пользователей.
Как прагматично мыслить об ошибках в рамках REST?
Давайте посмотрим на то как три популярных API подходят к данному вопросу.
Facebook:
HTTP Status Code: 200
{
"type": "OauthException",
"message":"(#803) Some of the aliases you requested do not exist: foo.bar"
}
Twilio:
HTTP Status Code: 401
{
"status" : "401",
"message": "Authenticate",
"code": 20003,
"more info": "http://www.twilio.com/docs/errors/20003"
}
SimpleGeo:
HTTP Status Code: 401
{
"code": 401,
"message": "Authentication Required"
}
Чтобы не произошло при запросе к Facebook вы получите код ответа 200 - все OK. Многие сообщения об ошибках также смещены в ответ HTTP. В примере приведен код ошибки (803), но не указано, что она из себя представляет и как её обрабатывать.
Twilio
Twilio делают хорошее дело согласуя ошибки с кодами статусов HTTP. Подобно Facebook они предоставляют более точное описание ошибки, но еще дополняют его ссылкой на документацию. Комментарии и обсуждения документации сообществом помогают создать информационную базу и обеспечивают более широкий контекст для разработчика встретившегося с этими же ошибками.
SimpleGeo
SimpleGeo предоставляют в ответе только коды ошибок без дополнительной информации.
Некоторые лучшие практики
Используйте коды статусов HTTP.
Используйте коды статусов HTTP и старайтесь аккуратно отображать их на соответствующие стандартные коды.
Существует более 70 кодов статусов HTTP. Однако, большинство разработчиков не помнят их все наизусть. Поэтому, использование не очень распространенных кодов заставит прикладного разработчика отвлечься от его приложения и обратиться к Wikipedia чтобы понять то, что вы хотели ему сказать.
По этой причине большинство провайдеров API используют лишь небольшое подмножество кодов. Например, Google GData API использует только 10 кодов статусов, Netflix - 9, а Digg только 8.
Google GData:
200,201304400,401,403,404,409,410500
Netflix:
200,201304400,401,403,404,412500
Digg:
200400,401,403,404,410500,503
Сколько статусов использовать в своём API?
По большому счету, возможны только 3 различных исхода взаимодействия между приложением и API:
- Все работает - успех
- Приложение делает что-то неправильно - клиентская ошибка
- API делает что-то неправльно - ошибка сервера
Начните с использования следующих трех кодов. Если понадобится - добавьте еще. Но вам не следует выходить за рамки 8-ми кодов.
200- OK400- Bad Request (неверный запрос)500- Internal Server Error (внутренняя ошибка сервера)
Если вам не хочется сводить все состояния к 3-м приведенным выше, то попробуйте выбрать что-то из следующих 5-ти:
201- Created (ресурс создан)304- Not Modified (ресурс не изменился)404- Not Found (ресурс не найден)401- Unauthorized (не авторизованный запрос)403- Forbidden (запрос запрещен)
Важно чтобы возвращаемый код мог быть принят и обработан бизнес-логикой приложения, например, в выражении if-then-else или case.
Делайте возвращаемые сообщения настолько подробными насколько это возможно.
Коды для кодов:
200- OK401- Unauthorized
Сообщения для людей:
{
"developerMessage": "Verbose, plain language description of the problem for the app developer with hints about how to fix it.",
"userMessage": "Pass this message on to the app user if needed.",
"errorCode": 12345,
"more info": "http://dev.teachdogrest.com/errors/12345"
}
В общем, будьте подробны и используйте простые описания. Добавьте все подсказки, которые ваша API-команда посчитает подходящими для того, чтобы указать на возможную причину ошибки.
Мы очень рекомендуем добавлять в описание ссылку на дополнительную информацию, как это делает Twilio.
Советы по версионированию
Версионирование является одним из наиболее важных вопросов при проектировании Web API.
Никогда не публикуйте API без версии, и делайте указание версии обязательным.
Давайте посмотрим на то как реализовано версионирование у трех популярных API:
- Twilio -
/2010-04-01/Accounts - salesforce.com -
services/data/v20.0/sobjects/Account - Facebook -
?v=1.0
Twilio использует метку времени в URL (Европейский формат).
Во время сборки приложения разработчик указывает дату компиляции. После эта дата указывается во всех HTTP-запросах.
При получении запроса Twilio выполняют поиск. На основании полученной метки времени они определяют какое API соответствовало данному моменту времени и соответственно перенаправляют запрос.
Это очень продуманный и интересный подход, хотя мы и думаем, что он несколько сложен. Например, может быть не очень понятно, что представляет собой эта метка времени - дату компиляции или дату публикации API.
Salesforge.com использует v20.0, размещенный где-то в URL.
Нам нравится использование нотации v.. Но, нам не нравится .0 по той причине, что это подразумевает частое изменение интерфейса. Логика, лежащая за интерфейсом, может меняться часто, но сам интерфейс должен оставаться стабильным.
Facebook также использует нотацию v., но делая версию необязательным параметром.
Это довольно проблематичный подход, т.к. как только Facebook станет по-умолчанию использовать API следующей версии, приложения не включающие номер версии могут стать дефектными.
Как прагматично думать о номерах версий в REST?
Никогда не публикуйте API без версии. Делайте указание версии обязательным.
Указывайте версию с префиксом v. Размещайте ее у левого края URL, чтобы она имела наиболее широкую область действия (например, /v1/dogs).
Используйте простые целые числа. Не используйте нотацию с точкой (например, v1.2) потому что это подразумевает более подробное версионирование, что не очень хорошо работает с API - это интерфейс, а не реализация. Придерживайтесь v1, v2 и т.д.
Сколько версий нужно поддерживать? Поддерживайте, по крайней мере, одну старую версию.
Как долго поддерживать версию? Дайте разработчикам на реагирование хотя бы один цикл.
Иногда это 6 месяцев, иногда - 12. Это зависит от платформы разработки, типа приложения и пользователей. Например, мобильным приложениям требуется для адаптации больше времени, чем веб-приложениям.
Где должна быть версия и формат? В URL или в заголовках?
Существует сильная школа касательно вопроса размещения формата и версии в заголовке.
Иногда разработчики вынуждены размещать версию в заголовке из-за наличия множества взаимосвязанных API. Обычно, это является симптомом более общей проблемы, а именно того, что они публикуют внутренний бардак, вместо создания единого, удобного для применения фасада.
Но это не значит, что размещение версии в заголовке является симптомом проблемного API, совсем нет!
В действительности, использовать заголовки более правильно по нескольким причинам: это является частью стандарта HTTP, это концептуально соответствует версионированию по Филдингу, это решает некоторые проблемы с взаимосвязанным API, и т.д.
Однако, мы думаем, что причиной редкого использования является неудобство работы из браузера.
Простые правила которых мы придерживаемся:
- если версия влияет на логику обработки запроса, для большей видимости размещайте её в URL
- если она не влияет на логику обработки каждого запроса, как информация OAuth, размещайте ее в заголовке
Все приведенные ниже примеры представляют собой один и тот же ресурс:
dogs/1
Content-Type: application/json
dogs/1
Content-Type: application/xml
dogs/1
Content-Type: application/png
Код, обрабатывающий каждый из этих запросов, может значительно отличаться между собой.
В этом случае нет сомнений для использования заголовков, т.к. это представляет собой устоявшуюся практику.
Пагинация и частичный ответ (partial response)
Частичный ответ позволяет возвратить разработчику только необходимую для него информацию.
Для примера рассмотрим получение твитов (tweet) с помощью API Twitter. Вы получаете намного больше, чем требуется для обычного twitter-приложения: имя персоны, текст твита, время отправки, количество ретвитов, и много метаданных.
Давайте посмотрим как некоторые популярные API решают проблему получения только необходимой информации, включая API от Google, которые одними из первых применили на практике идею частичного ответа.
/people:(id,first-name,last-name,industry)
Этот запрос персон возвращает ID, фамилию, имя, и сферу деятельности.
LinkedIn реализует частичную выборку используя краткий синтаксис, - :(...), - который не является очевидным. Вдобавок, разработчикам трудно изучать и анализировать API используя поисковый движок.
/joe.smith/friends?fields=id,name,picture
?fields=title,media:group(media:thumbnail)
Google и Facebook используют схожий подход, который хорошо себя зарекомендовал.
Они оба используют необязательный параметр fields в значении которого перечисляются имена необходимых полей.
Как видно из примера, для получения информации из дополнительных ресурсов можно использовать подобъекты.
Необязательное указание полей для выборки задавайте в списке через запятую.
Подход Google работает очень хорошо.
Ниже приведен пример того как получить только необходимую информацию от нашего собачьего API используя данный подход:
/dogs?fields=name,color,location
При таком подходе URL легко читать, разработчик может выбрать только необходимую приложению информацию, а количество данных, передававемых по сети, при этом снижается, что актуально для мобильных приложений.
Синтаксис частичной выборки, также, может использоваться для запроса связанных дополнительных ресурсов, что уменьшает количество необходимых для получения информации запросов.
Предоставляйте разработчикам простой механизм пагинации объектов в БД.
Чаще всего возврат всех ресурсов в БД является плохой идеей.
Давайте посмотрим как Facebook, Twitter и LinkedIn реализуют постраничный вывод. Facebook использует параметры offset и limit. Twitter использует страницы (page) и rpp (число записей на странице). LinkedIn использует start и count.
По смыслу, Facebook и LinkedIn делают одно и то же, т.е. start и count LinkedIn используется точно также как и offset и limit Facebook.
Получение записей от 50-й до 75-й у каждой системы:
- Facebook -
offset=50иlimit=25 - Twitter -
page=3иrpp=25 - LinkedIn -
start=50иcount=25
Используйте limit и offset.
Мы рекомендуем limit и offset. Эти названия являются простыми и общепринятыми.
/dogs?limit=25&offset=50
Метаданные
Также, мы рекомендуем в каждый постраничный ответ включать метаданные, показывающие разработчику доступное число записей.
Как насчет значений по-умолчанию?
Мои значения постраничного вывода по-умолчанию - это limit=10, а offset=0.
Эти значения, конечно же зависят от объема ваших данных. Если ресурсы являются тяжелыми, то, вероятно, лучше ограничить их числом меньшим 10. Если ресурсы небольшие, то, возможно, имеет смысл выбрать большее значение для лимита.
В итоге:
- обеспечивайте возможность частичного ответа с помощью необязательного параметра
fieldsи списка полей через запятую; - для реализации постраничного вывода (pagination) используйте параметры
limitиoffset.
Как насчет ответов без ресурсов?
Вызовы API ответы которых, по существу, не являются ресурсами не такая уж и редкость.
Действия, подобные приведенным ниже, являются признаками того, что мы имеем дело не с ресурсом.
- Calculate
- Translate
- Convert
Например, вы хотите реализовать простой алгоритм расчета того сколько кому-то надо заплатить налогов, или трансляцию естественного языка (в запросе один язык, в ответе - другой), или сделать конвертер валют. Ни что, из перечисленного выше, не использует объекты БД.
В этом случае:
Используйте глаголы вместо существительных.
К примеру, API для конвертации 100 евро в китайские юани:
/convert?from=EUR&to=CNY&amount=100
Явно обозначьте в документации к API отличия данного не-ресурсного сценария.
Просто выделите в отдельный раздел документации описание того, что вы используете глаголы в случаях когда некоторое действие используется для генерации или расчета чего-то на основании информации запроса, вместо получения ресурса.
Поддержка различных форматов
Мы рекомендуем поддерживать более одного формата, имея в виду отдачу ресурса в одном формате, а прием ресурса во всех необходимых форматах. Обычно имеется возможность автоматизации отображения одного формата в другой.
Вот как выглядит синтаксис для этого у некоторых популярных API:
Google Data
?alt=json
Foursquare
/venue.json
Digg
Accept: application/json
/resource?type=json // при наличии переопределяет заголовок Accept
Digg обеспечивает указание формата двумя способами: чисто по-REST’овски в заголовке Accept или с помощью параметра type в URL. Это может несколько путать и, по меньшей мере, в документации нужны пояснения к поведению в случае конфликта.
Мы рекомендуем подход Foursquare.
Получение коллекции или конкретного элемента в формате json:
dogs.json
/dogs/1234.json
Разработчики, или даже обычные пользователи любой файловой системы, знакомы с точечной нотацией (dot notation). Также, нужен лишь один дополнительный символ, - точка, - чтобы передать свое намерение.
Что насчет формата по-умолчанию?
По моему мнению, JSON побеждает в качестве формата по-умолчанию. JSON является наиболее близким к универсальному языку среди всего того, что мы имеем в наличии. Даже если серверная часть написана на Ruby on Rails, PHP, Java, Python и т.п., для разработки интерфейса в большинстве проектов используется JavaScript. Также у JSON есть еще одно преимущество - краткость (по сравнению, например, с XML).
Что насчет имен атрибутов?
В предыдущем разделе мы говорили о форматах - поддержке нескольких форматов и работе с JSON в качестве формата по-умолчанию.
Теперь давайте поговорим о том, что происходит после получения ответа.
У вас есть объект с данными в виде атрибутов. Как следует их именовать?
Рассмотрим ответы некоторых популярных API:
- Twitter:
"created_at": "Thu Nov 03 05:19;38 +0000 2011" - Bing:
"DateTime": "2011-10-29T09:35:00Z" - Foursquare:
"createdAt": 1320296464
Каждый из них использует различное соглашение. Хотя для меня, как разработчика использующего Ruby on Rails, более привычен подход Twitter, мы думаем, что способ Foursquare лучше.
Как ответы API попадают обратно в код? Мы парсим ответ (JSON-парсер) и заполняем объект тем, что получилось в итоге. Это выглядит примерно так:
var myObject = JSON.parse(response);
Если вы выберите подход Twitter или Bing, ваш код будет выглядеть как приведено ниже. Это не соответствует принятым в JavaScript соглашениям и выглядит странно - как-будто это имена какого-то другого объекта или класса в системе, что не является правильным.
timing = myObject.created_at;
timing = myObject.DateTime;
Рекомендации:
- По-умолчанию используйте JSON.
- Придерживайтесь стиля имен атрибутов принятого в JavaScript:
- используйте CamelCase;
- верхний или нижний регистр используйте в зависимости от типа объекта.
В итоге имена будут выглядеть так, как приведено ниже, давая возможность фронтенд-разработчикам писать код следуя принятым в JavaScript соглашениям.
"createdAt": 1320296464
timing = myObject.createdAt;
Советы по реализации поиска
Хотя простой поиск и можно смоделировать в виде API к ресурсу (resourceful API), например dogs/?q=red, более сложный поиск, затрагивающий несколько ресурсов, требует другого подхода к проектированию.
Это покажется уже знакомым если вы читали раздел посвященный использованию глаголов, а не существительных, когда вместо возврата ресурса из БД выполняется какое-то действие или вычисление.
Если вы хотите реализовать глобальный поиск среди нескольких ресурсов, мы советуем придерживаться модели используемой Google:
Глобальный поиск
/search?q=fluffy+fur
В этом случае search - это глагол, а ?q представляет запрос.
Ограниченный поиск
Задание области поиска можно реализовать его указанием в начале пути. Например, поиск собак владельца с ID 5678 будет выглядеть следующим образом:
/owners/5678/dogs?q=fluffy+fur
Заметьте, что мы отказались от явного использования ресурса search в URL, и ограничиваем область поиска с помощью параметра q.
Отформатированный результат
В запросах на поиск или любое другое действие (не-ресурс) можно дополнительно указывать формат, как это показано ниже:
/search.xml?q=fluffy+fur
Объединение API в поддомен
До этого мы говорили о том, что находится в URL за доменом. Теперь давайте разберемся с другой стороной.
Вот примеры того как это работает у Facebook, Foursquare и Twitter:
- У Facebook опубликовано два API. Она начали с
api.facebook.com, а потом модифицировали его нацелив на работу с социальным графом (social graph).
graph.facebook.com
api.facebook.com
- У Foursquare одно API.
api.foursquare.com
- У Twitter опубликовано три API, два из которых ориентированы на работу поиска и стриминг.
stream.twitter.com
api.twitter.com
search.twitter.com
Легко понять причину того, что Facebook и Twitter имеют больше одного API. Внедрение требует времени, а перенастроить CName DNS на другой кластер - просто.
Но если отталкиваться от интересов прикладного разработчика, то мы рекомендуем использовать подход Foursquare:
Объединяйте все API в единственный поддомен.
Для разработчиков, создающих крутые приложения используя ваше API, это будет более прозрачным, простым, и понятным.
Facebook, Foursquare и Twitter, также, имеют специальные порталы для разработчиков.
developers.facebook.com
developers.foursquare.com
dev.twitter.com
Как это все организовать?
Шлюз вашего API должен быть доменом верхнего уровня, например, api.teachdogrest.com.
Придерживаясь духа REST, адрес вашего портала для разработчиков должен соответствовать такому шаблону:
developers.teachdogrest.com
Перенаправляйте
Теперь, в качестве варианта, вы можете перенаправлять разработчика туда куда он, как вы думаете, хотел попасть.
Скажем, разработчик вводит в строке браузера api.teachdogrest.com, но сервер не обрабатывает GET-запрос для этого адреса, и вы можете спокойно перенаправить его на ваш портал и помочь найти то за чем он, в действительности, пришел.
api–>developers(в случае GET)dev–>developersdeveloper–>developers
Советы по обработке исключительных ситуаций
До этого мы говорили о нормальном, стандартном поведении API.
В этом разделе мы рассмотрим некоторые исключения, которые имеют место когда клиенты Web API не в состоянии использовать все перечисленные выше механизмы. Например, иногда клиенты перехватывают коды ошибок HTTP или поддерживают ограниченный набор HTTP-методов.
Как обойти эти ситуации и продолжать работать в рамках ограничений таких клиентов?
Клиент перехватывает коды ошибок HTTP
Некоторые версии Adobe Flash обладают одной общей особенностью - в случае если ответ HTTP-запроса имеет код отличный от HTTP 200 OK, Flash-контейнер его перехватывает и выводит напрямую пользователю.
Из-за этого, разработчики приложений не могут перехватывать коды ошибок и нужно чтобы API каким-то образом это обеспечивало.
Twitter отлично подошли к данной проблеме.
Они ввели необязательный параметр suppress_response_codes. Если suppress_response_codes установлен в true, ответ всегда имеет код 200.
/public_timelines.json?suppress_response_codes=true
HTTP status code: 200
{"error":"Could not authenticate you."}
Заметьте, что результатом указания этого параметра является подробный код ответа (они могли бы указывать причину ошибки, но решили возвращать подробное описание).
Очень важно и должно быть учтено, что коды ошибок будут игнорироваться, т.к. это напрямую влияет на поведение клиентскиго приложения.
Общие рекомендации:
- Используйте
suppress_response_codes=true. - Коды HTTP больше не только ради самих кодов.
Правила предыдущего раздела об обработке ошибок также меняются. Теперь HTTP-коды будут игнорироваться. Клиент не будет проверять код статуса HTTP, т.к. он всегда будет одним и тем же.
Помещайте коды статуса HTTP в сообщение ответа.
В примере ниже код ответа - 401 и его можно увидеть в сообщении. Также включайте в это сообщение дополнительные коды ошибок и подробную информацию.
Всегда возвращайте OK:
/dogs?suppress_response_codes=true
Код для игнорирования:
200 - OK
Сообщение для людей и приложения:
{
"response_code": 401,
"message": "Verbose, plain language description of the problem with hints about how to fix it.",
"more_info": "http://dev.tecachdogrest.com/errors/12345",
"code" : 12345
}
Клиент поддерживает ограниченный набор методов HTTP
Использование GET и POST более распространено, чем PUT и DELETE.
Для обеспечения целостности концепции 4-х HTTP-методов мы рекомендуем применять следующий, часто используемый разработчиками на Ruby on Rails, подход:
Обеспечьте возможность указания метода с помощью необязательного параметра запроса.
Из-за этого методом всегда будет GET, но разработчик сможет выразить все глаголы HTTP придерживаясь при этом чистого REST API.
Создание:
/dogs?method=post
Чтение:
/dogs
Обновление:
/dogs/1234?method=put&location=park
Удаление:
/dogs/1234?method=delete
Предупреждение: опасно обеспечивать возможность создания или удаления ресурсов используя метод GET, т.к., если URL размещен на странице, то веб-пауки вроде Googlebot могут случайно создать или удалить какие-либо данные. Убедитесь, что вы точно осознаете последствия обеспечения данного механизма в контексте вашего приложения.
Аутентификация
Есть множество точек зрения относительного этого вопроса. Я не всегда согласен с коллегами из Apigee насчет того как реализовывать аутентификацию.
Давайте посмотрим на три популярных сервиса. Реализация у каждого из них отлична от остальных.
- PayPal - Permissions Service API
- Facebook - OAuth 2.0
- Twitter - OAuth 1.0a
Отметим, что проприетарное трехногое (three-legged) API прав доступа PayPal существовало задолго до OAuth.
Что делать вам?
Используйте самый последний и крутой OAuth - OAuth 2.0 (на момент написания). Это означает, что веб- или мобильным приложениям, использующим API, не надо передавать пароль. Это позволяет API-провайдеру отзывать токены для конкретного пользователя или всего приложения не требуя, при этом, изменения пароля пользователя. Очень важно иметь такую возможность в случае взлома каким-либо образом устройства или в случае выявления машеннического приложения.
Прежде всего OAuth 2.0 означает повышение безопасности и улучшение опыта работы с веб- и мобильными приложениями.
Не делайте что-то вроде OAuth, но другое. Вряд ли разработчики обрадуются невозможности использования существующих библиотек для OAuth из-за ваших модификаций.
Осуществление запросов к API
Давайте посмотрим как выглядят некоторые запросы и ответы нашего собачьего API.
Создание коричневой собаки по кличке “Эл”:
POST /dogs
name=Al&furColor=brown
Response: 200 OK
{
"dog": {
"id": "1234",
"name": "Al",
"furColor": "brown"
}
}
Переименование “Эл” в “Ровер” (обновление):
PUT /dogs/1234
name=Rover
Response: 200 OK
{
"dog":{
"id":"1234",
"name": "Rover",
"furColor": "brown"
}
}
Получение информации о конкретной собаке:
GET /dogs/1234
Response: 200 OK
{
"dog":{
"id":"1234",
"name": "Rover",
"furColor": "brown"
}
}
Получение информации о всех собаках:
GET /dogs
Response: 200 OK
{
"dogs": [
{
"dog": {
"id":"1233",
"name": "Fido",
"furColor": "white"
}
},
{
"dog": {
"id": "1234",
"name": "Rover",
"furColor": "brown"
}
}
],
"_metadata": [
{
"totalCount": 327,
"limit":25,
"offset":100
}
]
}
Удаление “Ровер”: :-(
DELETE /dogs/1234
Response: 200 OK
Болтливое API (Chatty APIs)
Давайте подумает о том как прикладные разработчики используют API, которые вы спроектировали, и что они делают когда API болтливое.
Представьте как разработчики будут использовать ваше API.
При проектировании API и ресурсов постарайтесь представить как разработчики будут им пользоваться, скажем, при создании UI, приложения для iPhone или каких-то других приложений.
Некоторые API при проектировании превращаются в очень болтливые в том смысле, что для создания простого UI или приложения приходится выполнять десятки или сотни обращений к серверу.
Иногда некоторые команды вместо разработки нормального, основанного на ресурсах REST API, просто создают несколько getter-ов и setter-ов в Java-стиле для нужд определенного UI.
Мы рекомендуем избегать этого. Вполне возможно создание нормального REST API не подверженного, при этом, болтливости.
Полностью расслабьтесь (be complete and RESTful) и реализуйте быстрый доступ.
Сначала спроектируйте API в соответствии с принципами прагматичного REST, а после реализуйте необходимые методы упрощающие работу.
Что имеется в виду под быстрым доступом? Например, если вы знаете, что для 80% всех ваших приложений будет нужен какой-то агрегированный ответ, то просто добавьте в ваше API еще один метод, который будет его возвращать.
Не делайте второе без первого. Сначала спроектируйте API последовательно используя принципы прагматичного REST!
Используйте синтаксис частичного ответа.
На помощь может прийти синтаксис частичного ответа, который мы обсуждали в одном из предыдущих разделов.
Избежать создания одноразового базового URL можно используя синтаксис частиных ответов для получения детальной информации о зависимых и связанных ресурсах.
В случае нашего собачьего API, у собаки есть владелец, который обращается к ветеринарам, и т.д. Для получения только необходимой информации реализуйте вложенный синтаксис частичного ответа с указанием полей через точку.
/owners/5678?fields=name,dogs.name
Предоставление SDK
Часто перед API-провайдерами встает вопрос - нужно ли сопровождать API библиотеками и SDK?
Если ваше API следует принятым практикам проектирования, последовательно, соответствует стандартам и имеет хорошую документацию, то разработчикам будет нетрудно с ним работать даже без клиентского SDK. Также совершенно необходимы хорошо документированные примеры кода.
С другой стороны, бывают сценарии когда создание UI требует неплохого знания предметной области. Это может стать проблемой даже в случае создания UI и приложений использующих API для довольно простой предметной области - вспомните об ограничении в 140 символов для основного объекта Twitter API.
Вы не должны изменять API в попытках преодолеть сложности предметной области. Вместо этого, вы можете сопроводить его библиотеками и SDK.
Это позволит вам не перегружать ваше API. Часто, бОльшя часть требуемых действий находится на стороне клиента и вы можете вынести все это в SDK.
SDK предоставляет необходимый код для конкретной платформы, который разработчики будут использовать в своих приложениях для вызовов операций не усложняя, тем самым, ваше API.
Другими причинами создания SDK для API могут быть:
- Ускорение внедрения для конкретной платформы. Например, SDK на Objective C для iPhone.
- Упрощение интеграции с вашим API. Актуально в случае когда ключевые сценарии использования сложны или от клиента требуется дополнительная стандартная обработка.
- SDK позволит сократить количество плохого или неэффективного кода, который может стать причиной снижения скорости работы сервиса.
- В качестве ресурса для разработчиков. Хорошее SDK приводит к созданию хороших примеров кода и документации. Примером тому могут служить Yahoo! и Paypal
- Продвижение вашего API в конкретном сообществе. Вы можете загрузить свое SDK с примерами кода или инструкциями по встраиванию на соответствующую страницу сообщества разработчиков целевой платформы.
Паттерн Фасад для API
На данном этапе может возникнуть вопрос:
Как нам следует мыслить с архитектурной точки зрения?
Как, следуя всем этим лучшим практикам, публикуя внутренние сервисы и системы для пользы разработчиков, продолжать развивать и поддерживать наше API?
Учетные бекэнд системы часто слишком сложны для непосредственной публикации сервисов прикладным разработчикам. Они стабильны (пройдя проверку временем) и надежны (обеспечивая ключевые функции вашего бизнеса). Но, обычно, они реализованы на устаревших технологиях и не всегда просты для публикации в рамках таких веб-стандартов как HTTP. Такие системы могут обладать сложными взаимосвязями и очень медленно модифицироваться не успевая за потребностями разработчиков мобильных приложений и изменениями форматов данных.
В действительности, задача заключается не в разработке API для единственной большой системы, а в создании API вокруг массива дополняющих друг друга систем, каждая из которых должна быть задействована для придания API ценности с точки зрения прикладного разработчика.

Полезным будет рассмотрение нескольких анти-паттернов с которыми нам приходилось встречаться. Ниже мы попробуем объяснить почему считаем, что они не работают.
Стратегия Наращивания (Build Up)
При использовании стратегии наращивания разработчик предоставляет доступ к основным объектам большой системы и поверх этого располагает слой чтения\создания XML.
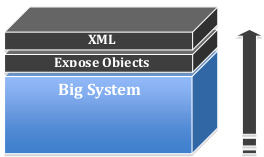
Достоинствами данного подхода являются скорость выпуска первой версии и то, что разработчики API уже в курсе деталей работы системы.
К сожалению, внутренности системы на уровне объектов могут быть слишком детализированными и непонятными для внешних разработчиков. Также, при данном подходе, наружу проявляются детали внутренней архитектуры, что вряд ли можно назвать хорошей идеей. Данный подход может не обеспечивать требуемой гибкости, т.к. API, в этом случае, точно отражает работу самой системы. Если кратко, то наращивание функционала эталонной системы в виде API может быть слишком сложным.
Статегия Комитета по стандартам (The Standards Committee)
Часто внутренними системами владеют и управляют люди и подразделения c различающейся точкой зрения на то как все должно работать. Проектирование API, используя стратегию Комитета по стандартам, часто включает создание стандартных документов определяющих схемы, URL-ы и т.п., а все заинтересованные участники ведут разработку для достижения единой цели.
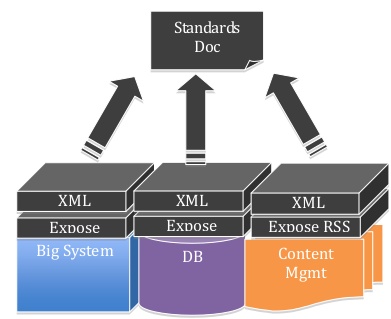
Достоинством данного подхода является быстрое получение первой версии API. Вы, также, можете поспособствовать созданию определенной унификации и общей стратегии, что само является значительным достижением в случае крупных организаций состоящих из автономных единиц.
Недостатком данной стратегии является (возможно) долгая реализация. Даже в случае быстрого создания необходимых документов реализация может быть длительной и не всегда соответствовать принятым соглашениям. Также данный подход может стать причиной посредственной архитектуры из-за слишком большого количества принятых компромиссов.
Стратегия Подражания (Copy Cat)
Иногда мы видели этот подход у поздно появившихся на рынке компаний, например в случае когда их конкурент уже успел вывести свое решение в массы. Эта стратегия, также, может обеспечить быстрое создание первой версии API. Вдобавок, в случае если прикладные разработчики, которые будут использовать ваше API, уже знакомы с API конкурента, вы получите прогнозируемую кривую восприятия (adoption curve).
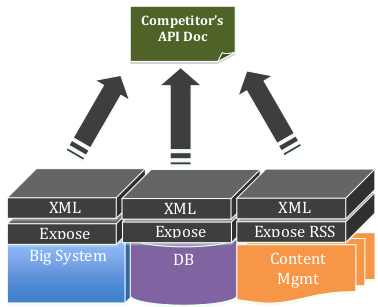
Однако, это может привести к недифференцированному продукту, который будет воспринят как более низкий по качеству на рынке API. Вы можете утратить собственные ключевые свойства и идентичность из-за простого копирования чьего-то API.
Решение - Паттерн Фасад для API
Лучшее решение начинается с размышлений об основах продукт-менеджмента. Вашему продукту (API) должны доверять, он должен быть полезным, уместным и выделяться на фоне других, а ваш продукт-менеджер является ключевым участником команды работающей над API.
Как только ваш продукт-менеджер определился с общей картиной, остальное - задача архитекторов.
Мы рекомендуем вам реализовывать паттерн фасад для API. Этот подход даст вам буферную зону или виртуальный слой между верхнеуровневым интерфейсом и низкоуровневой реализацией API. Фактически вы создаете фасад - исчерпывающее представление того каким должно быть API и того, что является важным с точки зрения прикладного разработчика и конечного пользователя создаваемого приложения.
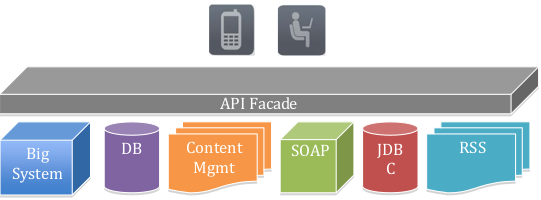
Вверху на этой схеме расположены разработчик и приложение, использующее API. Фасад API изолирует разработчика, приложение и API. Создание простой архитектуры на уровне фасада дает возможность декомпозиции одной действительно сложной проблемы на несколько меньших.
Используйте паттерн фасад когда хотите предоставить простой интерфейс к сложной подсистеме. Часто подсистемы усложняются по мере развития.
Приемы объектно-ориентированного проектирования. Паттерны проектирования
(Э. Гамма, Р. Хелм, Р. Джонсон, Д. Влиссидес)
Реализация паттерна фасад API включает три основных шага:
- Проектирование идеального API - проектирование URL’ов, параметров запросов и ответов, форматов данных, заголовков, способов выборки и т.д. Архитектура API должна быть последовательной.
- Реализация архитектуры с заглушками для данных. Это позволит прикладному разработчику начать использовать ваше API и давать обратную связь еще до взаимодействия с внутренними системами.
- Создание связи или интеграция между фасадом и системами.
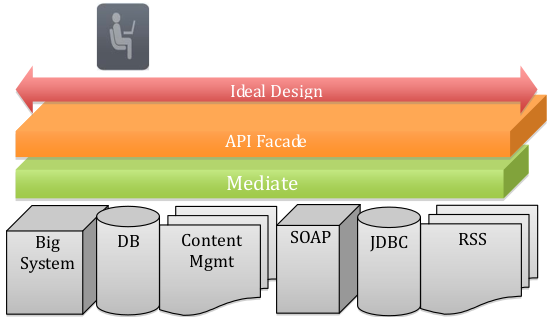
Используя трех-шаговый подход вы разбиваете одну большую проблему на три меньших проблемы. Если вы попробуете решить одну большую проблему, то начнете с кода и будете двигаться от бизнес-логики (учетной системы) к простому интерфейсу API. Возможно, вы будете выставлять наружу объекты или таблицы или RSS-канал для всех источников данных, и перед публикацией для приложения преобразовывать все это в соответствующий формат в виде XML. Такой, ориентированный на взаимодействие компьютер-компьютер, подход к публикации приложения трудно реализовать правильно.
Применение паттерна фасад помогает отойти от функционального подхода в нескольких ключевых моментах. Во-первых, у вас есть возможность обсуждения всех трех шагов по-отдельности, что даст остальным более полное понимания прагматичного подхода к архитектуре решения. Во-вторых, в этом случае фокус смещается с самого приложения на прикладного разработчика. Цель заключается в том, чтобы убедиться, что разработчик приложения может успешно использовать ваше API, архитектура которого последовательна и интуитивно понятна.
По причине того, что предметом обсуждения является архитектура, фасад можно рассматривать в виде довольно интересного шлюза. Мы можем доверить ему однообразную реализацию общих паттернов (постраничный вывод, выборка, упорядочивание, сортировка и т.д.), аутентификации, авторизации, версионирования, и т.п. для всего API (это большая тема и полное рассмотрение выходит за рамки этой статьи).
Еще одним преимуществом для команды разработчиков API является более легкая адаптация к разнообразным вариантам использования независимо от того, исходят ли они от внутренних разработчиков, партнеров или клиентов. Команда API будет способна поддерживать темп требуемых разработчикам изменений, включая постоянно развивающиеся протоколы и языковые средства. Также, в этом случае, более просто осуществляется расширение API новыми возможностями основной системы или подключение дополнительных существующих систем.
Ресурсы
- Representational State Transfer (REST), Roy Thomas Fielding, 2000
- RESTful API Design Webinar, 2 nd edition, Brian Mulloy, 2011
- Apigee API Tech & Best Practices Blog
- API Craft Google Group